
How crul + Gen2 RPA gets data that transforms your business
February 8, 2023 – Carl Yestrau and Nic Stone, Co-Founders Crul, Inc.
When we created crul, we wanted to give RPA developers the ability to query any data across the modern enterprise technology stack. Unfortunately, data isn’t organized and stored in one easy-to-access place. Instead, data is distributed across a loosely coupled system of ever-changing technologies.
What is crul?
Think of crul as kind of like a "data accordion." At its core, crul is a map/reduce/expand engine with a query language that empowers users to transform web pages and API requests into shapeable data sets. Crul makes it easy to access, crawl, shape, organize, enrich, and clean data from just about anywhere and deliver it to just about anywhere.
The name crul comes from a mashup of the word "crawl" (as in web crawling) and "curl," one of our favorite tools for interacting with the web. crul was built from our desire to transform the web (open, SaaS, API, and dark) into a dynamically explorable data set in real-time.
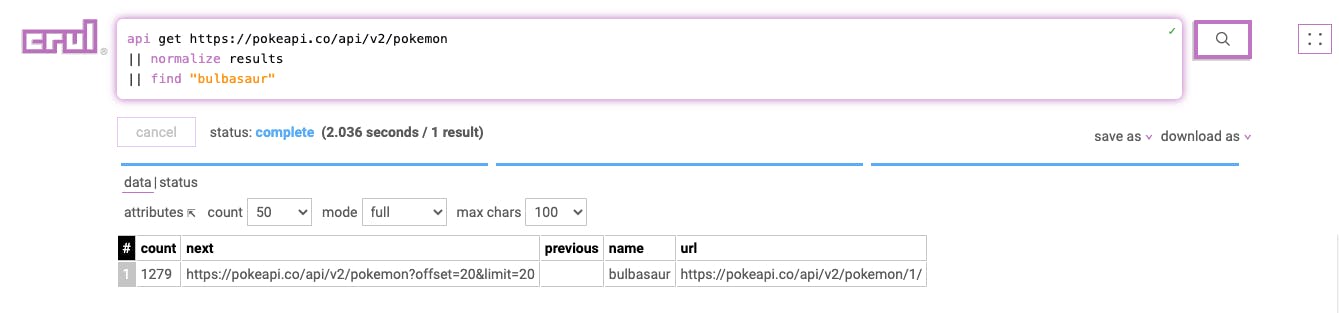
Let’s look at a crul query language example. We can start with a core api command to make an API request, then pipe the API request's results to a normalize operation (breaking out each result into a separate row), and finally, a find "keyword" command, which will search for "keyword" in the API request results. Here's what that query and results might look like in crul:
api get https://pokeapi.co/api/v2/pokemon
|| normalize results
|| find "bulbasaur"
crul meets Robocorp
A few months ago, through our friends at Harpoon Ventures, we had the opportunity to share our company vision and product demo with the Founder and CEO of Robocorp, Antti Karjalainen. Subsequently, we began working with Tommi Holmgren, VP of Solutions at Robocorp, on a cool use case and our first Robocorp Portal bot.
Use Case: Let’s go shopping for a great deal.
It was recently the holiday season, and if you’re anything like Nic and I, you may be spending more time hacking than shopping. So in our first use case, we decided to explore extracting data from a Shopify website to get prices on some products.
Here are the Shopify use case requirements:
- Open the Shopify product listing page
- Iterate through each product listing page
- Extract the relevant product information and shape / transform the data into a digestible format
- Export the data as a .csv file
Get started with a crul query
The primary way to use crul is through authoring and running queries. These queries are composed of one or more stages, "piped" together using the double pipe || syntax. If you are familiar with the Unix/Linux shell, crul language will seem rather familiar.
TLDR; Just show me the query!
open https://www.tentree.ca/collections/mens-shorts --html --hashtml
|| filter "(attributes.class == 'justify-between product-attr-container mt-2 relative')"
|| sequence
|| html innerHTML
|| filter "(_html.nodeName == 'A') or (_html.attributes.class == 'flex' or _html.attributes.class == 'text-discount-price')"
|| excludes _html.innerHTML "line-through"
|| table _html.innerText outerHTMLHash _sequence
|| groupBy outerHTMLHash
|| rename _group.0._html.innerText product
|| rename _group.1._html.innerText price
|| sort _group.0._sequence --order "ascending"
|| addcolumn time $TIMESTAMP.ISO$
|| table product price time
Query Breakdown
Let's break down this query - stage by stage - to extract a table of products, prices, and timestamps from a web page - using the crul query language.
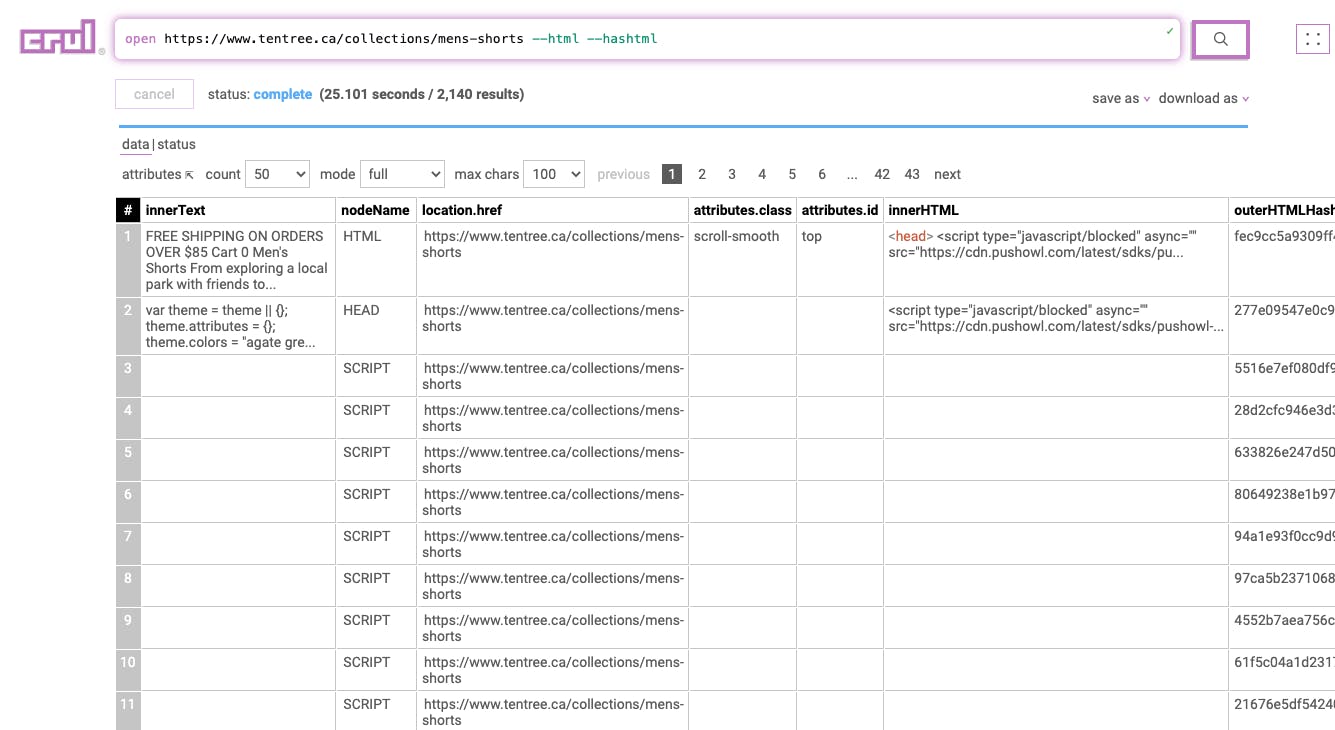
Stage 1
Query:
open https://www.tentree.ca/collections/mens-shorts --html --hashtml
This stage opens the provided URL, renders the page, and transforms it into a tabular structure that includes the HTML and hashes of the HTML for future grouping.
Results:
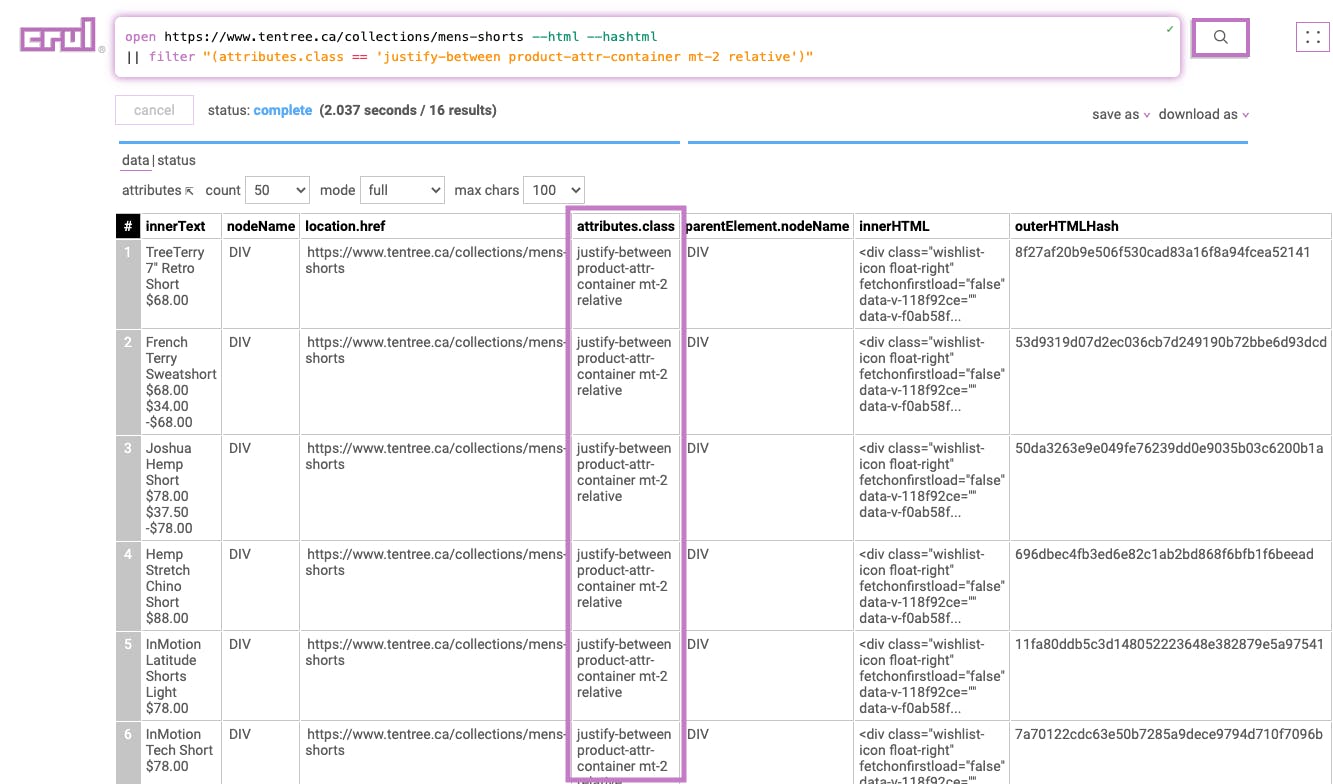
Stage 2
|| filter "(attributes.class == 'justify-between product-attr-container mt-2 relative')"
This stage filters the page data to only include elements matching the filter expression.
Results:
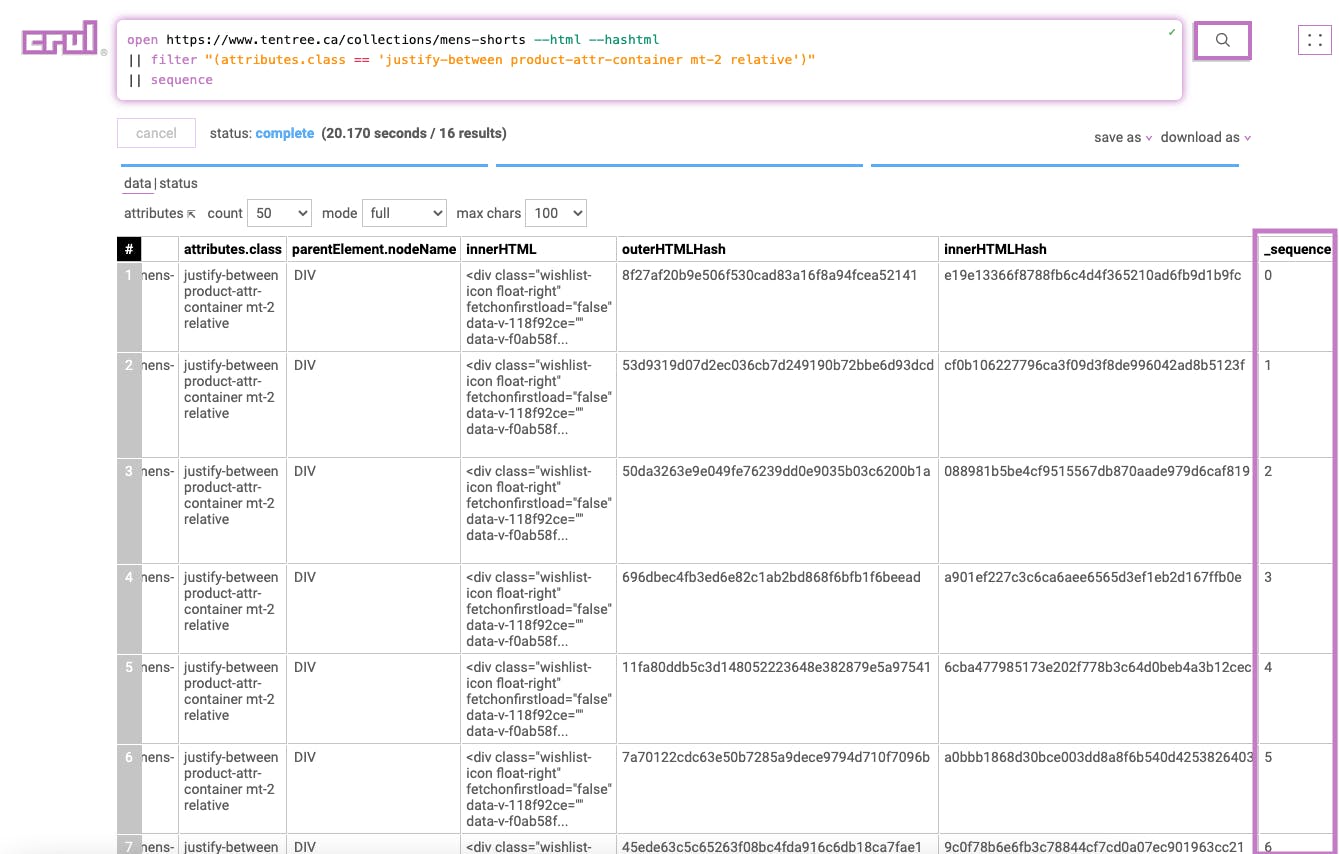
Stage 3
|| sequence
This stage will add a _sequence column to each row containing the row number.
Results:
Stage 4
|| html innerHTML
This stage processes the element HTML into a row for each of its children. Note that the element hash is shared by each of the expanded children, allowing us to group them back together.
Results:
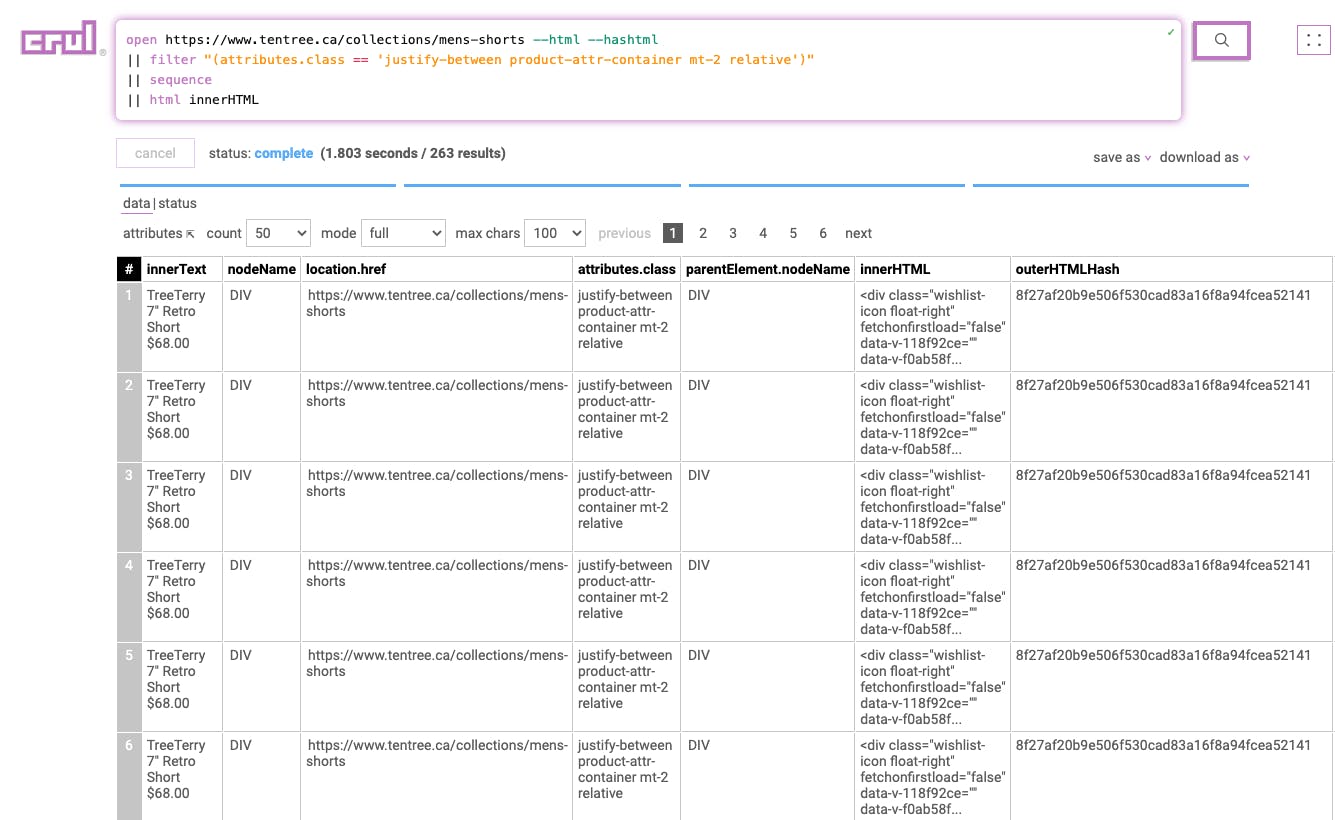
Stage 5
|| filter "(_html.nodeName == 'A') or (_html.attributes.class == 'flex' or _html.attributes.class == 'text-discount-price')"
This stage filters the page data to only include elements matching the filter expression.
Results:
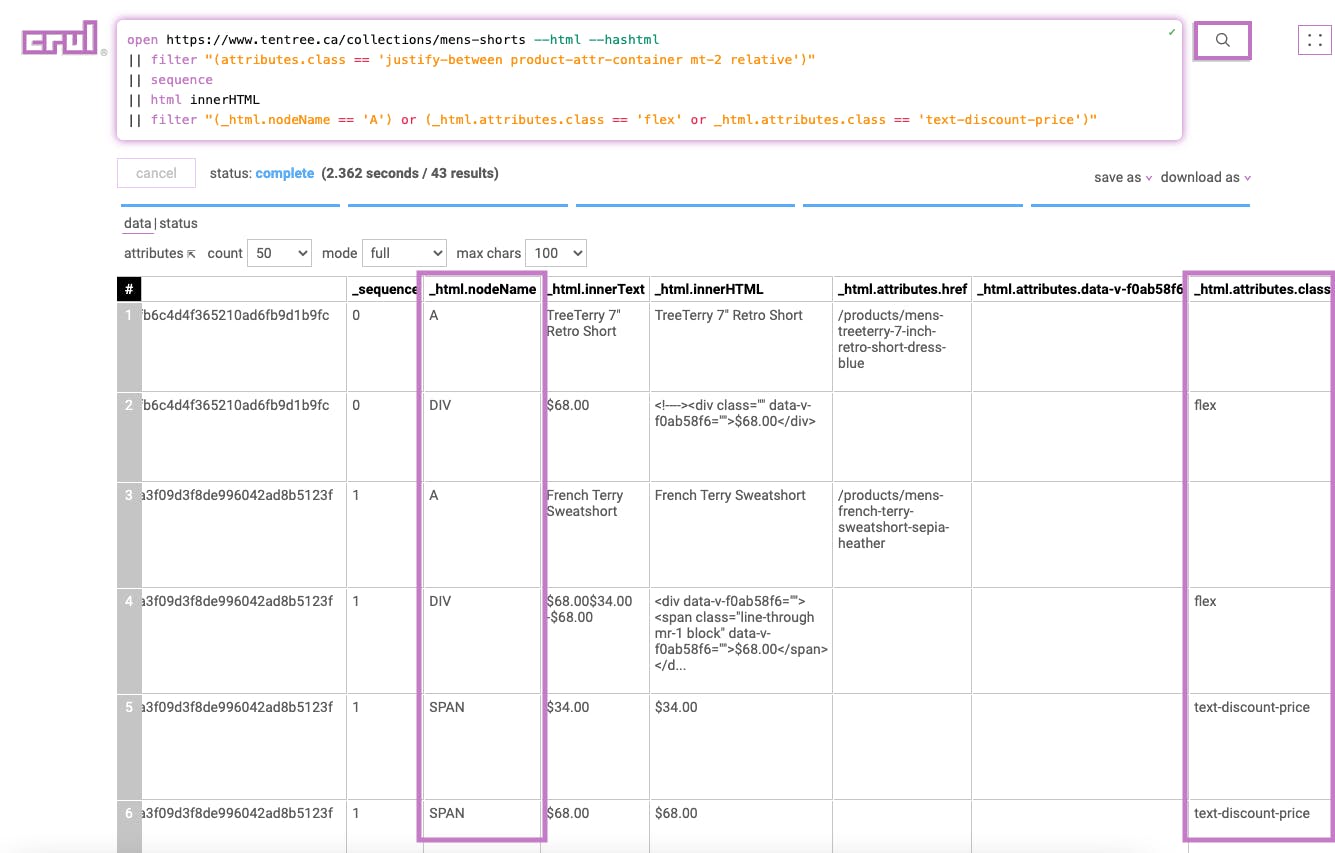
Stage 6
|| excludes _html.innerHTML "line-through"
This stage excludes any row containing the value “line-through” in the _html.innerHTML. For example, the data set includes both the regular price and the sale price, so this stage will remove the regular price entry.
Results:
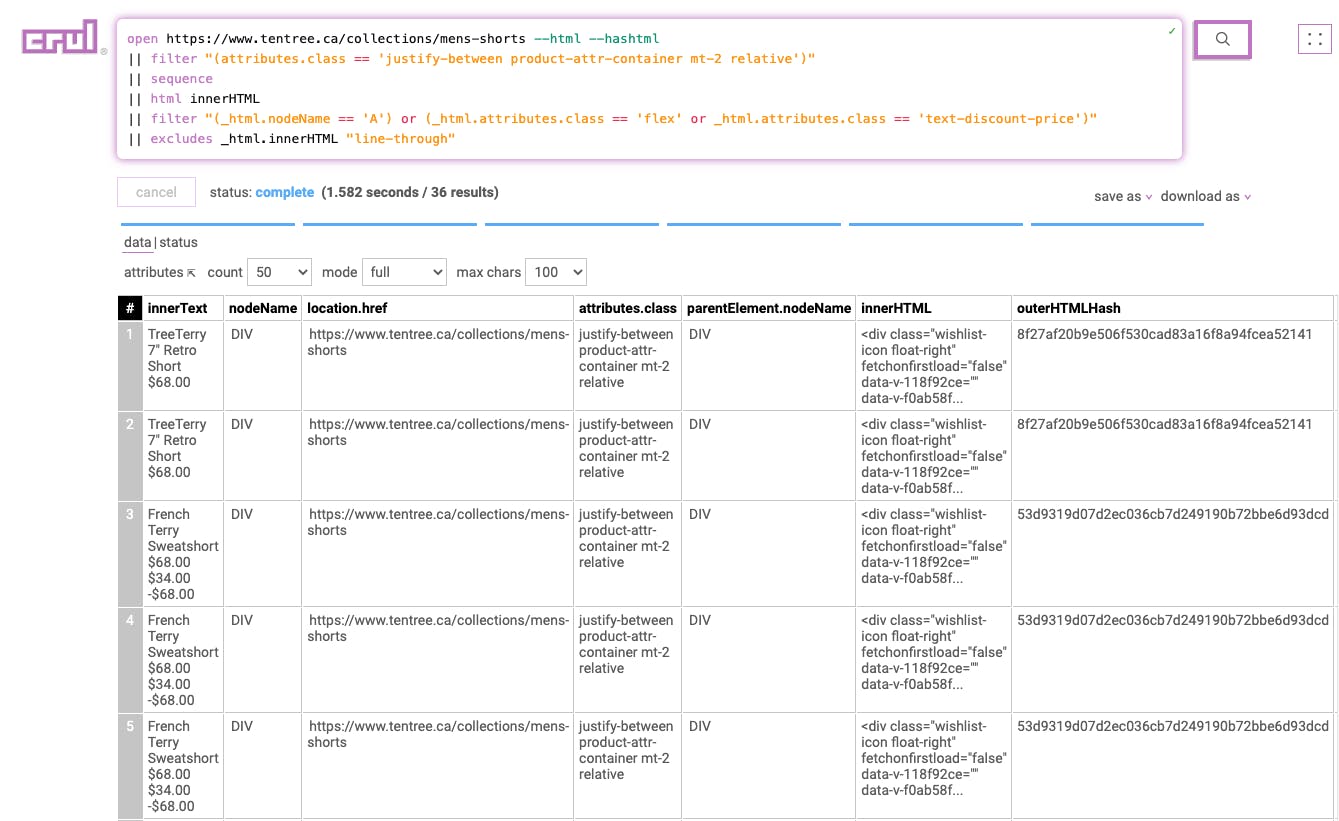
Stage 7
|| table _html.innerText outerHTMLHash _sequence
This includes only the desired columns in the data set.
Results:
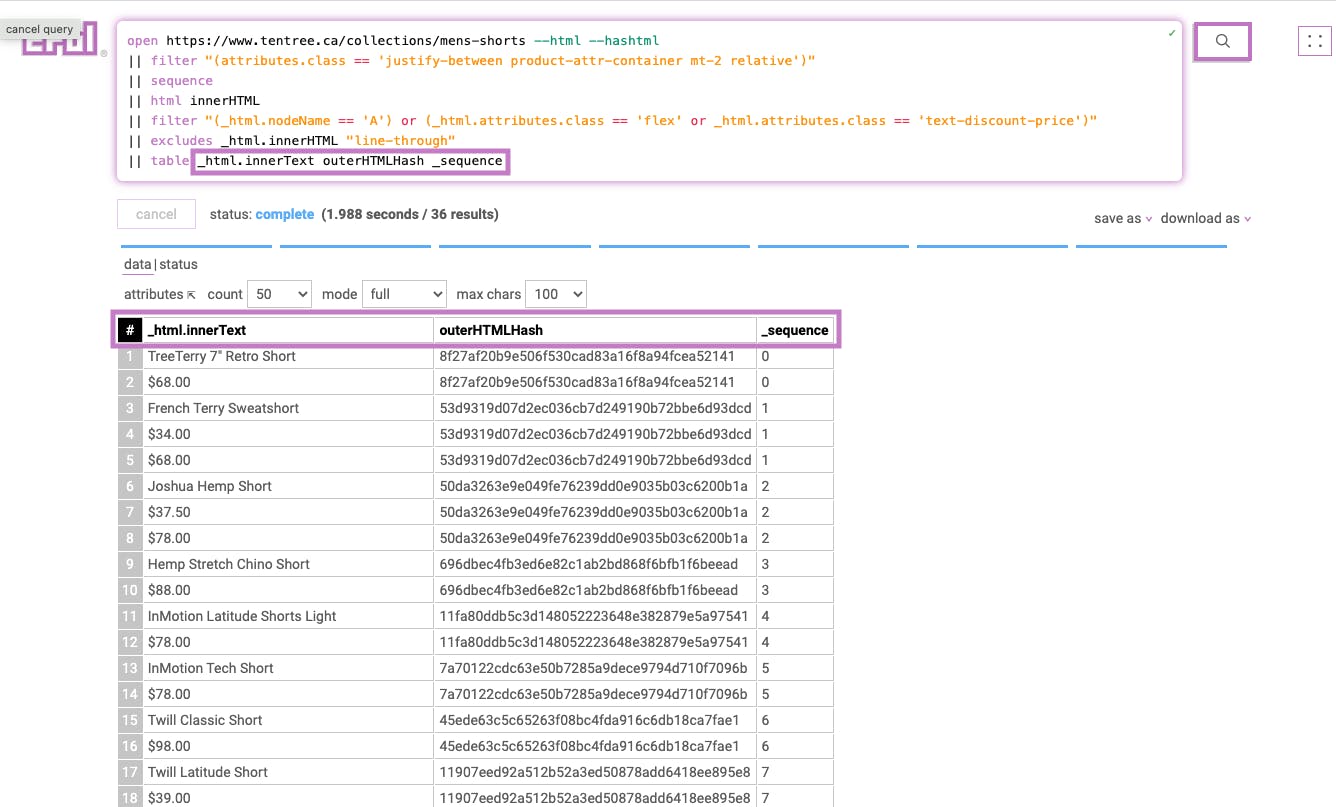
Stage 8
|| groupBy outerHTMLHash
This stage groups page elements by the parent hash calculated per element in the first stage of this query.
Results:
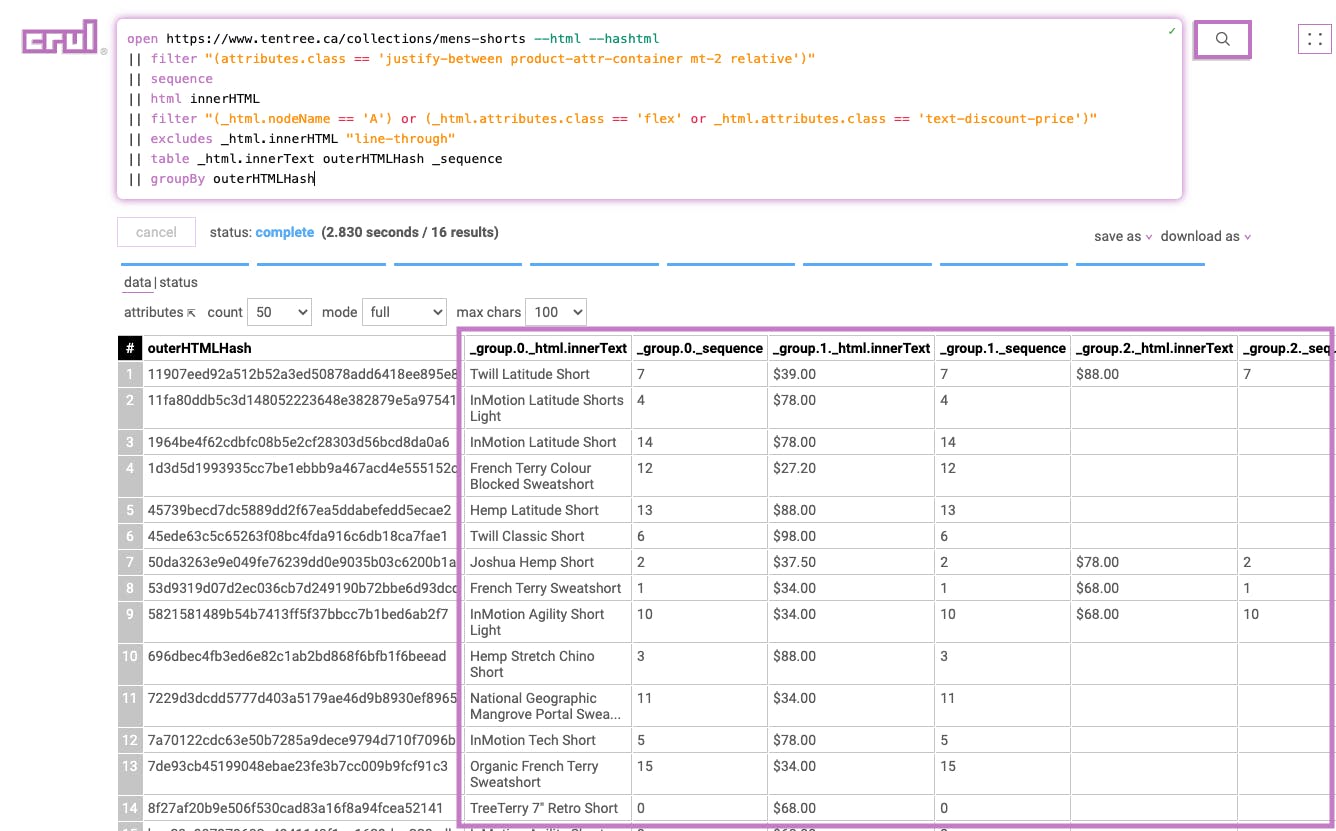
Stage 9
|| rename _group.0._html.innerText product
This stage renames the _group.0._html.innerText column to product.
Results:
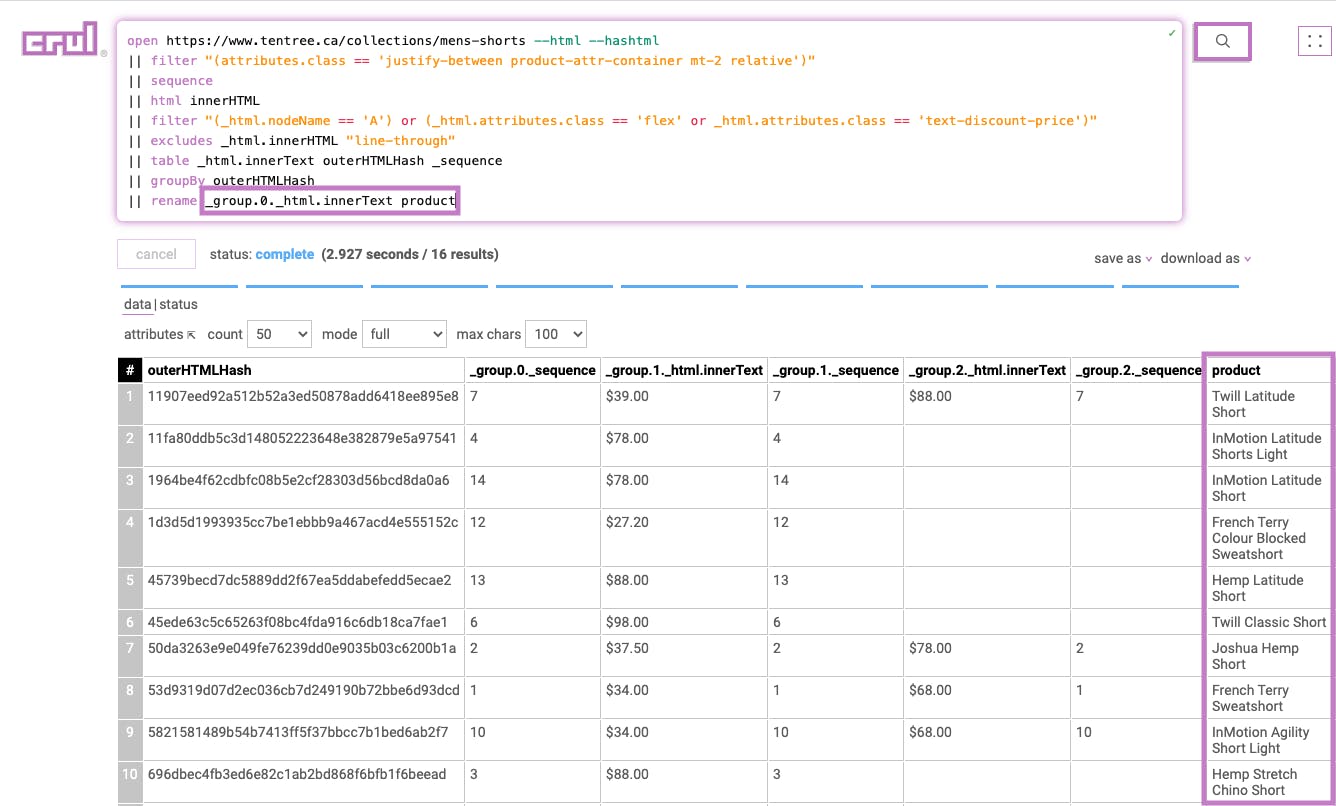
Stage 10
|| rename _group.1._html.innerText price
This stage renames the _group.1._html.innerText column to price.
Results:
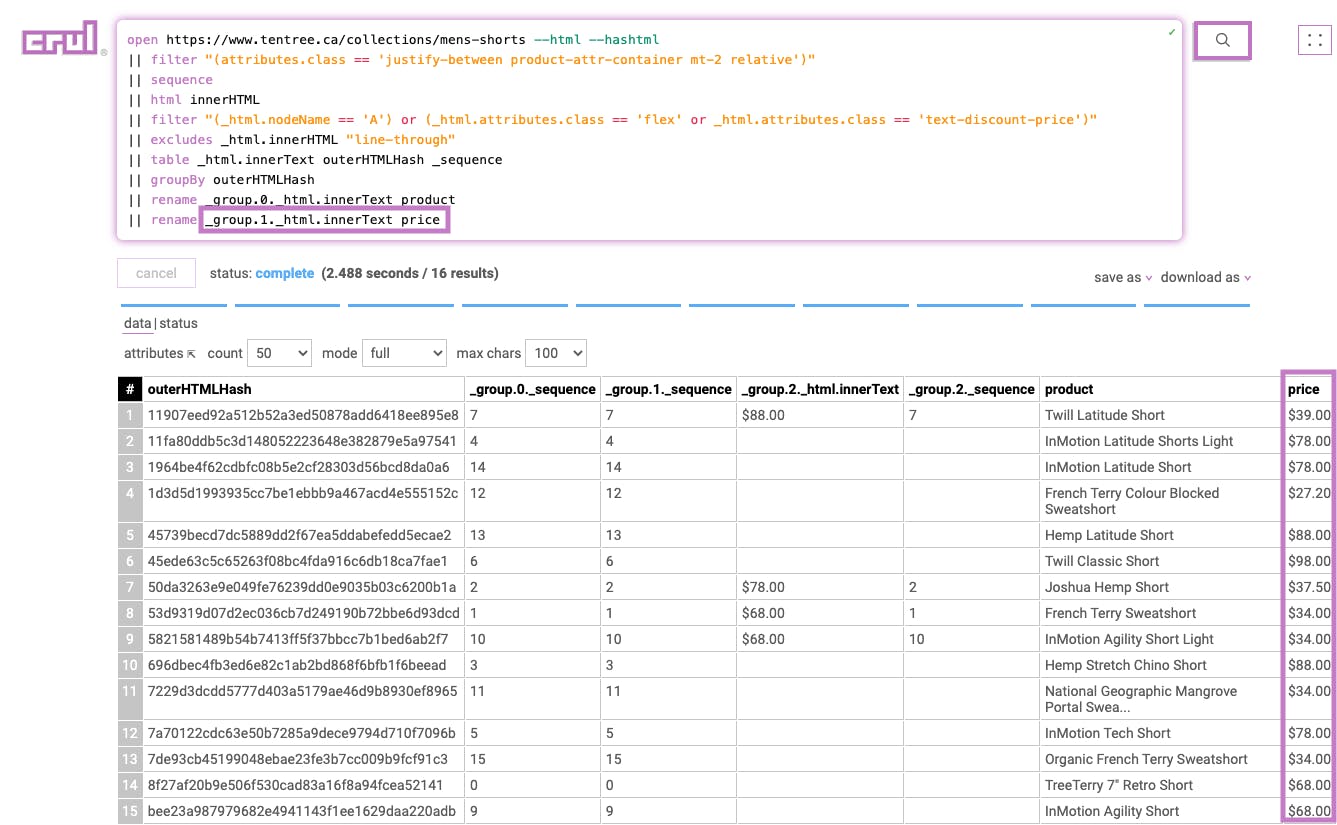
Stage 11
|| sort _group.0._sequence --order "ascending"
This sorts the list according to the previously added sequence number in ascending order to preserve the order of products as they appear on the page.
Results:
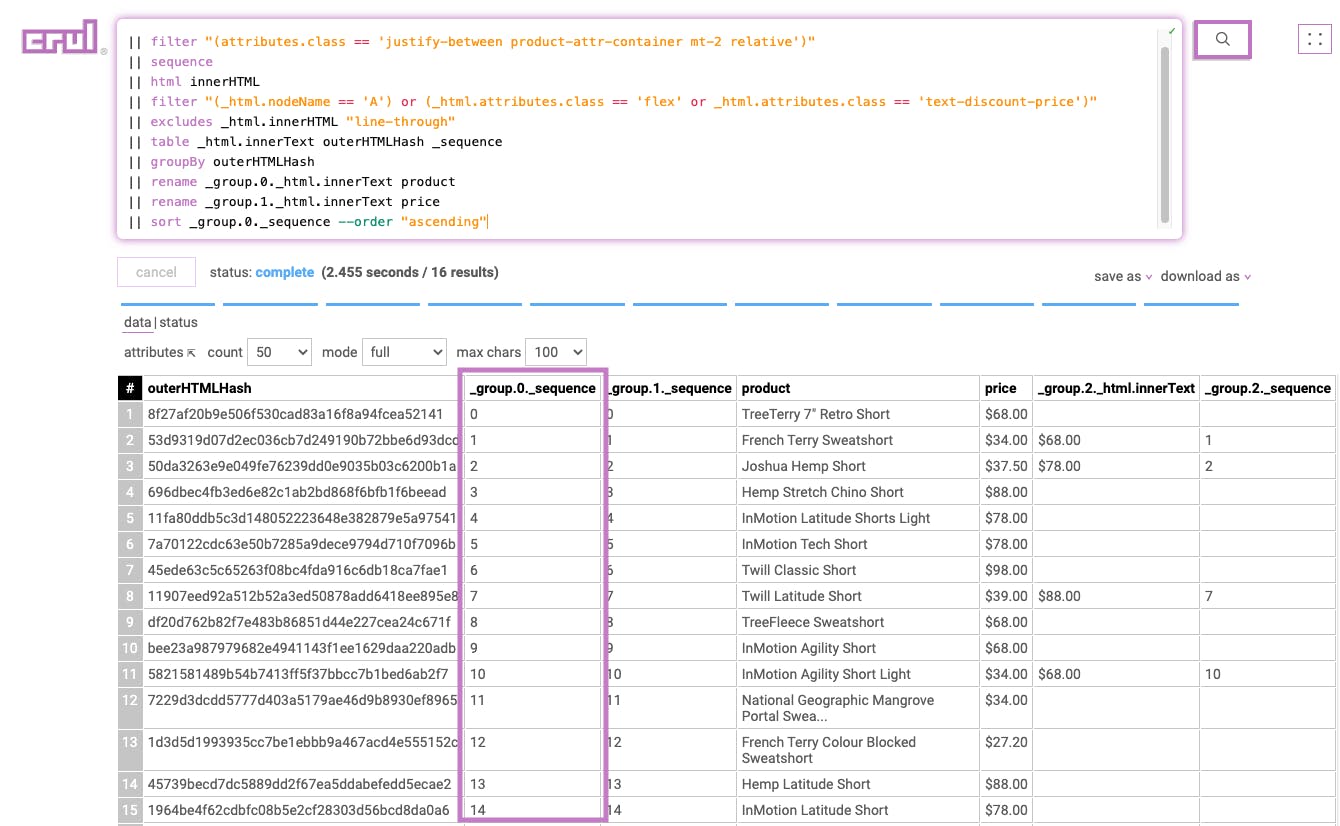
Stage 12
|| addcolumn time $TIMESTAMP.ISO$
Adds a timestamp column with the current ISO timestamp to each row.
Results:
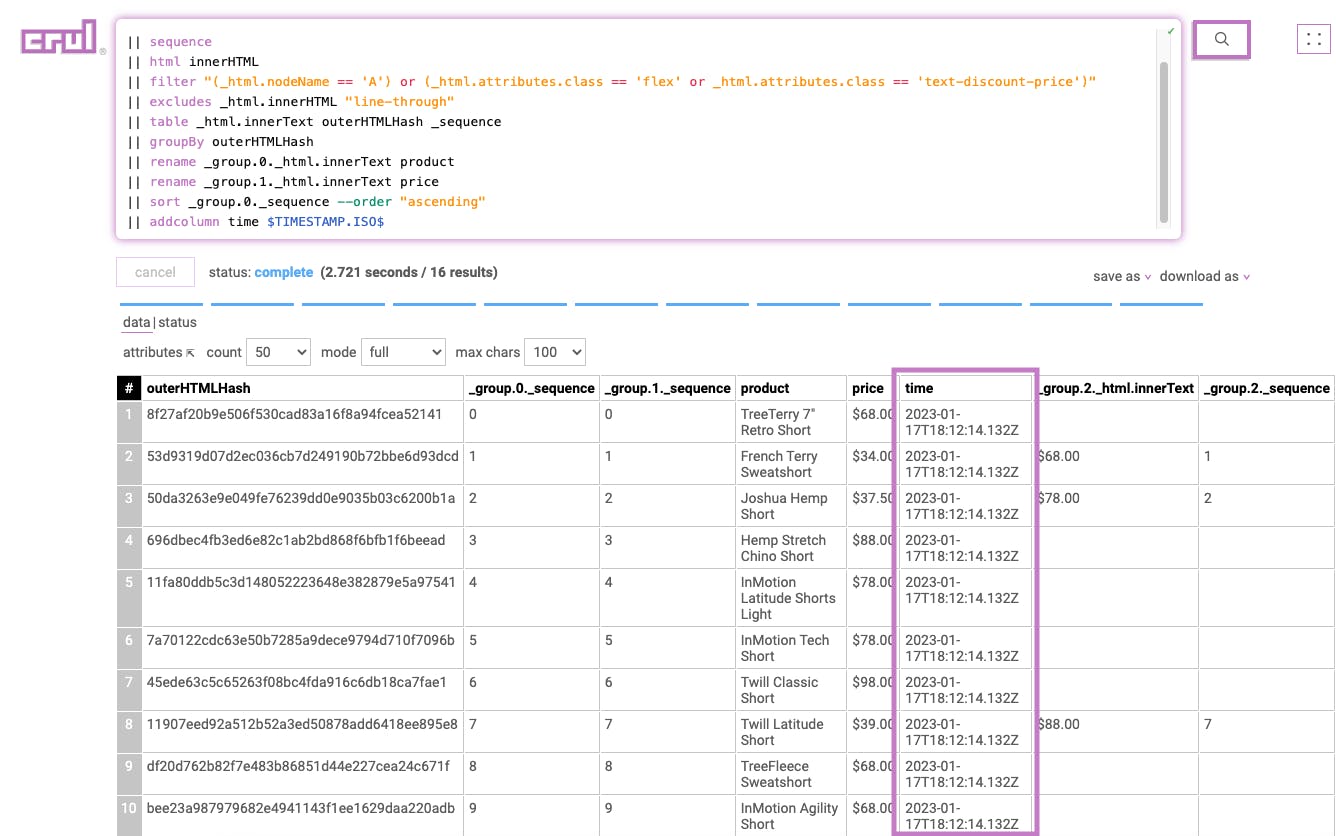
Stage 13
|| table product price time
This includes only the desired columns in the final set of results.
Results:
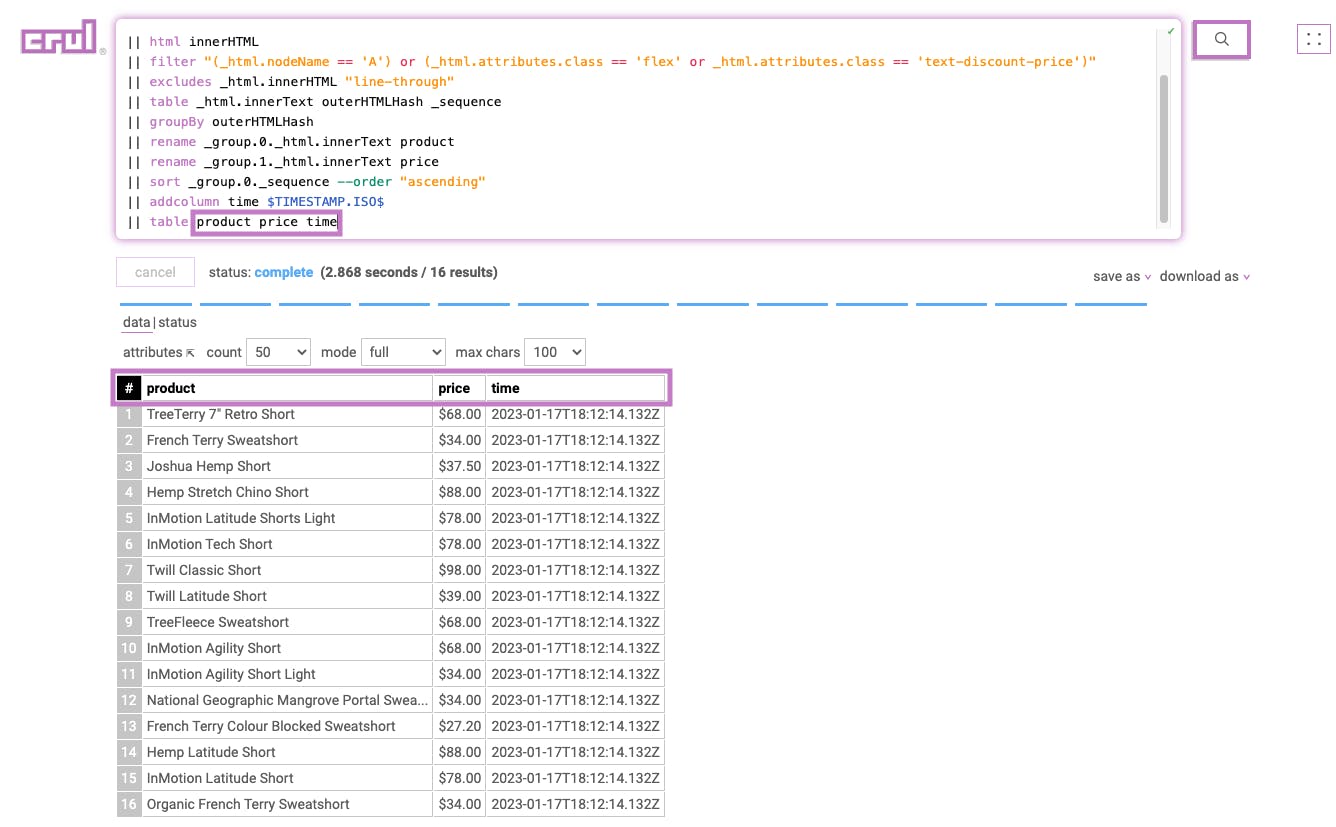
Huzzah!
We did it! Next, let's integrate crul with your Robocorp script. Additionally, you could use crul to immediately download these results as a CSV or JSON file or push directly to several common destinations (S3, Kafka, Splunk, etc.).
Integrating into your Robocorp RPA
Robocorp example bot
crul’s API is an easy one for any bot, and one option is to simply use RPA.HTTP library to make calls from the robot code to the API and get back the results. However, in this example, we wanted to demonstrate Robocorp’s capability to extend robots with Python and made a simple wrapper that deals with the crul API and exposes a clean “Run Query” keyword to robots. The file is available here.
Having the wrapper in place, the robot code remains ultra-clean and easy to read. What is needed is to shoot the query shown above to the keyword and make a table out of the results. Like this:
(code)
${results}= Run Query ${query}
${table}= Create Table ${results}
After that, it’s all up to you what to do with the data. Our example bot appends the data into an Excel spreadsheet
Get the complete robot example from the Robocorp Portal.
Get crul API Key
Documentation on the creation of a crul API key is available here.
Conclusion
crul is a new way of capturing data from any source, organizing it in tabular form, and leveraging it for virtually any purpose. The Shopify use case was a simple example of how the query language works - but it easily scales to tackle your most complex enterprise data needs. crul is lightweight and freely available for download with enterprise cloud and on-prem offerings, which pack a big punch.
When paired with Robocorp’s Gen2 RPA platform, you can automate virtually any business process 3x faster and at ⅓ of the cost. This deeply cuts your automation's total cost of ownership and accelerates your return on investment.
Start your digital transformation by signing up and downloading crul and using Robocorp today.